Introduction
This article will explore the architecture and components of a sophisticated chatbot built using Retrieval-Augmented Generation (RAG) to deliver precise and contextually aware responses. The system integrates Hugging Face embeddings, Chroma for vector storage, Fast API for the API, and the Llama 3 model from Groq Cloud for generating responses. Let’s break down how these components work together and understand the use cases for such a chatbot.
What is a Chatbot?
Before delving into the RAG chatbot, let’s first explain what a chatbot is. A chatbot is an AI-driven software designed to simulate human-like conversations with users through text or voice interfaces. It can interpret and process user queries, provide relevant responses, or perform specific tasks. Chatbots leverage natural language processing (NLP) and machine learning algorithms to improve their language understanding and generate appropriate replies.
Common Use Cases for Chatbots
Customer Support: Chatbots can automate responses to frequently asked questions, troubleshoot issues, or escalate complex cases to human agents, improving customer service efficiency.
E-commerce: By guiding users through product catalogues, answering queries, or assisting in the checkout process, chatbots enhance the online shopping experience.
Healthcare: Chatbots can book appointments, provide symptom checks, or offer general health advice, improving access to healthcare services.
Lead Generation and Marketing: Businesses use chatbots to engage potential customers, qualify leads, and provide personalised recommendations, enhancing user engagement and conversions.
HR and Recruitment: Chatbots streamline recruitment by conducting initial interviews, scheduling, and answering job-related queries.
Internal Operations: They can assist employees in IT support, HR inquiries, or administrative tasks, automating internal workflows.
What is LLM and RAG?
In the world of artificial intelligence (AI) and natural language processing (NLP), two concepts have gained significant traction: Large Language Models (LLMs) and Retrieval-Augmented Generation (RAG). These technologies represent the forefront of AI-driven language generation, providing new ways for machines to understand and generate human language in contextually relevant ways. Let’s dive into these terms and how they revolutionise AI applications.
Large Language Models (LLMs)
LLMs are neural networks trained on vast amounts of text data to understand and generate human language. Some of the most notable examples include GPT (Generative Pre-trained Transformer) by OpenAI, Llama by Meta, and BERT (Bidirectional Encoder Representations from Transformers) by Google.
LLMs are characterised by their massive size, often involving billions or even trillions of parameters, which allow them to handle complex tasks such as text generation, question answering, summarisation, and translation. The key advantage of LLMs lies in their ability to understand the intricacies of language, including context, tone, and meaning, making them extremely powerful for various NLP applications.
Retrieval-Augmented Generation (RAG)
While LLMs are incredibly powerful, they do have limitations. One major limitation is that LLMs do not always have access to up-to-date information, as they are limited to the data they were trained on. This is where Retrieval-Augmented Generation (RAG) comes into play.
RAG combines the capabilities of LLMs with external information sources. It enhances text generation by retrieving relevant information from databases, knowledge sources, or external documents, making the generated text more accurate, context-aware, and dynamic. The RAG approach effectively improves the factual accuracy and relevance of the responses generated by the model.
How RAG Works:
Step 1: Retrieval: Instead of relying solely on pre-trained knowledge, RAG retrieves relevant information from external sources, such as search engines, databases, or vector stores.
Step 2: Generation: The LLM uses the retrieved information to generate a more contextually accurate response.
This combination of retrieval and generation allows RAG to produce responses that are grounded in real-time, accurate, and specific information.
LLMs and RAG are reshaping the way we interact with AI-driven systems. LLMs offer powerful language understanding and generation capabilities, while RAG brings in real-time, relevant information to enhance the accuracy and applicability of AI responses. Together, these technologies are opening new doors in fields ranging from customer support and healthcare to content creation and beyond.
Components and Workflow
Creating a RAG chatbot system requires a combination of data embedding, real-time interaction capabilities, and efficient document retrieval mechanisms. This article explores the core components and workflow behind such a chatbot, focusing on embedding data for retrieval, handling user conversations, and generating responses using Retrieval-Augmented Generation (RAG).
Data Embedding
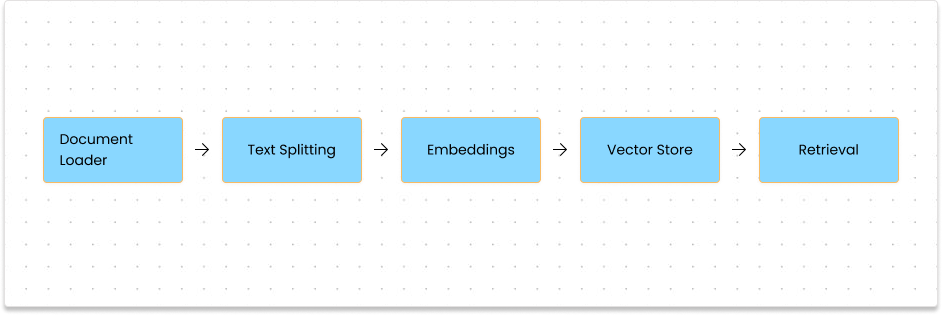
Data embedding is essential to ensure that the chatbot can access and retrieve relevant information during interactions. The embedding process converts text data into vectors, which represent the semantic meaning of documents, allowing quick retrieval when necessary.
Hugging Face Embeddings: The chatbot employs Hugging Face’s all-MiniLM-L6-v2 embedding model, transforming text (like PDFs and documents) into vector representations. This model effectively captures the semantic relationships between words and phrases in the text.
Chroma Vector Store: Once embedded, the data is stored in Chroma, a vector database. This enables efficient similarity searches, allowing the chatbot to retrieve relevant information during user interactions.
{kind=link}
Figure 1. Generation of Vector database [1]
Fast API for Real-time Conversations
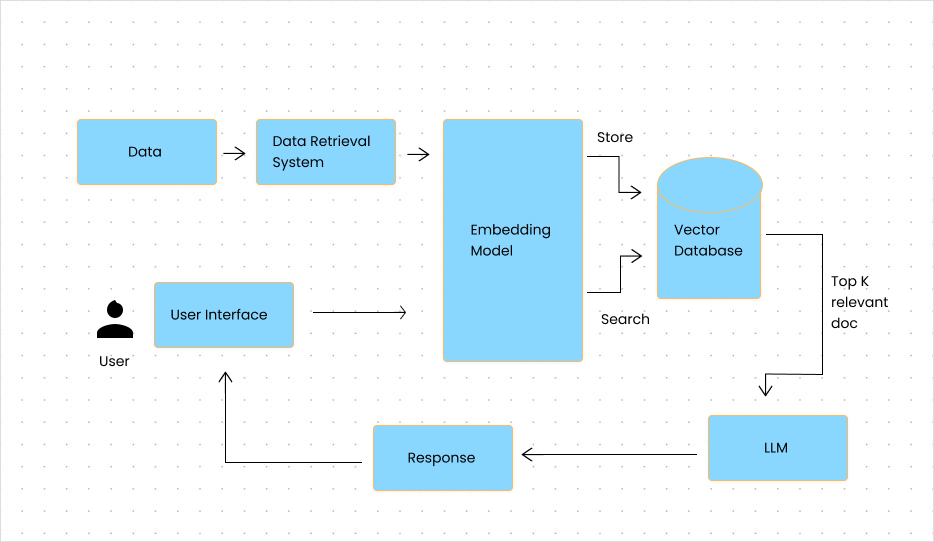
Fast API serves as the backbone for the chatbot’s web interface, handling real-time user interactions. This framework processes user inputs, retrieves relevant documents, and generates responses by interacting with the embedded data.
Integration with Llama 3: The chatbot leverages Groq Cloud’s Llama 3 model to generate accurate and meaningful responses. Once the system retrieves the relevant data, it sends this to the Llama 3 model, which crafts a response based on the contextual information.
Retrieval-Augmented Generation (RAG)
When a user queries the chatbot, it follows a Retrieval-Augmented Generation (RAG) workflow to provide a relevant and contextually accurate response.
Query Embedding: The user’s query is transformed into a vector using the same embedding model (all-MiniLM-L6-v2).
Retrieval: The chatbot queries Chroma using cosine similarity to identify relevant document chunks that match the query.
Response Generation: The retrieved data is passed to the Llama 3 model, which uses this context to generate a coherent and relevant response for the user.
{kind=link}
Conclusion
The chatbot’s combination of data embedding, real-time conversation management, and Retrieval-Augmented Generation allows it to deliver accurate, context-aware responses. With technologies like Fast API, Hugging Face embeddings, and the Llama 3 model, the system efficiently manages user interactions, document retrieval, and response generation, ensuring a smooth and engaging conversational experience.
REFERENCES
[1] Apocalypse Lab. “Langchain Unleashed: A Guide to Using Open Source LLM Models.” Udemy. Accessed April 22, 2024. https://www.udemy.com/course/langchain-unleashed-a-guide-to-using-open-source-llm-models .
Author: Zeba Najeeb
AI Solutions Architect & Developer